Building an Internal Wiki for Humans - maintained by LLM
Table of Contents
Introduction
Disclaimer - Humans.md
This post was written with love by an actual human. AI was only used for linting, formatting and house keeping. If you enjoy the content of this post (or any of my previous posts), please consider ☕ buying me a coffee ☕.
Now.. on to the content.. Enjoy!
A little bit about myself
People who have worked with me now or in the past may be able to verify that I am a little bit particular when it comes to documentation.
In my first IT job I was infamous for using the phrases “Is it documented?”, “Have you looked at the documentation?”, “Maybe we should document this!”. People did not enjoy these responses (I don’t know why), but more often than not the issue/process they came to raise happened to be documented and they would come to a resolution on their own by simply following the steps.
Anecdote 1 –> The holiday call
I distinctly remember a conversation where my boss once called me on holidays to say that a teammate did not know how to perform a task I usually did, I just told him to look at the documentation and told him the exact name of the internal process document. He hanged up, and 5 minutes later he messaged me to say I was right.
Sadly that is not the norm, and many times as engineers and product owners we take over projects and responsibilities that are not properly documented, only to have to reverse engineer impossibly complex solutions with nothing but our experience and intuition to navigate the logic behind the big and small decisions that result in the current state of project. The good ol’ “When I wrote this only me and God knew what this was meant to do, now only God knows”.
Anecdote 2 –> The turn-around
Another anecdote. I remember a few years ago I was having a conversation with my Tech Lead at the time (back when I was a true engineer and not a rusty manager 😜) and he looked at me in disbelief when I told him I actually enjoyed documenting stuff. Years later, the same Tech Lead would ask me if I had ever considered Technical Writing, after reading a review I made of a developer portal SaaS tool during an internal research project.
Not to brag - just saying. I guess even then I could not hide the passion. 🔥
‘Cool guys’ never document
Point is: I’ve always liked writing, and I did it a lot.. I hope you can tell.
Within the technical domain I’ve always worked hard to create meaningful commit messages, useful PR descriptions, accesible documents for end users and teammates, and more. Ever documented/built something so well that your previous work buddies contacted you to thank you some time after you left the job? (true story). In a market where often engineers switch jobs every couple years and live by the YoloOps mentality only caring about what cool thing they can do/learn next, I always felt proud to be remembered positively for the WHATxHOW, whatever my contribution may be to a project.
Regardless, I had come to believe that I was the odd one out, and I had accepted that perhaps this is just how things are in most companies, and that this behavior is inherent to our human nature. While it may be easier for me to write a poem, a blog or technical documentation for a project I made, I may struggle to perform basic calculations without my calculator app. On the contrary, there are those who seem to be physically unable to write more than 10 cohesive and meaningful words in a commit message to explain the rationale of the task that took them a whole day to solve.
However complex the implementation they’d just:
git commit -m "some changes"
Push directly to main without a care in the world, the code would then work perfectly on the first try because they are incredibly awesome engineers and they would move on with their lives without batting an eye. I like to imagine them like the cool guys in action movies that never look back at explosions. Their managers are like the angry and tired police chief that cannot control the loose cannon, so they reluctantly ignore their volatile methods as long as they produce results that allow them to get pat in the back by their own manager. I also imagine that if I were to ask them why they didn’t do better they’d just channel their inner John McClane and respond: “Look chief, you think you’re in charge? I’m the one crushing tickets like there is no tomorrow while you build presentations with your pals. My code is the documentation and that should be good enough”.
I just silently accepted that those people and I are wired differently. After all, they are getting shit done while I am sitting here writing my little word salads like a wannabe Cervantes of README.md. Maybe I was wrong, and they were right. Why waste time say lot word when few word do trick? Less word save time. Make world better. Right? Right!?
Why is documenting so hard ?
Documenting in the end, just like programming or riding a bicycle, is a skill. Getting good at any skill takes practice, and practice takes time. Many engineers (and non engineers alike) are unwilling to invest the time it takes to get good at documentation because for them it is not exciting, the same way for me it is not exciting to brush my teeth in the morning. It is just routine, something that needs to get done to deliver production-ready implementations. If the PM forgot to put the “document this” bullet point in the acceptance criteria of the task it should be fine to just ignore it, we can always add documentation later.
The truth is that producing exceptionally good documentation requires quite a lot of effort. It needs the writer to understand to a reasonable extent the topic that they are writing about, as Einstein once said: “[..] if you can’t explain it simply, you don’t understand it well enough”. It also requires empathy, because the writer needs to put themselves in the shoes of the target audience: “Am I being too technical?”, “Am I not being technical enough?”, “Do I need to include more screenshots or diagrams to support the explanation?”, “Will they get that reference from The Office if I casually include it in the middle of a rant?”
Documenting well requires continuous care, it would be easy enough if you could just document something perfectly just once and forget about it, but time moves on and things change. Documentation quickly becomes stale and must be updated, refactored, expanded, deprecated, while being internally consistent and mindful of whatever sees that documentation as a source of truth or dependency. All of this is specially problematic in technology, where things change incredibly fast and frequently. Keeping documentation up to date is a technical challenge on its own, as solutions get more complex and the documentation knowledge bases grow.
There are frameworks for documenting, tools for sharing and viewing documentation and keeping it well versioned, but until recently I had never encountered anything that addressed the core problem of the quality time investment it takes to build and maintain documentation with excellence and coherence. That all changed when I heard about the LLM Wiki.
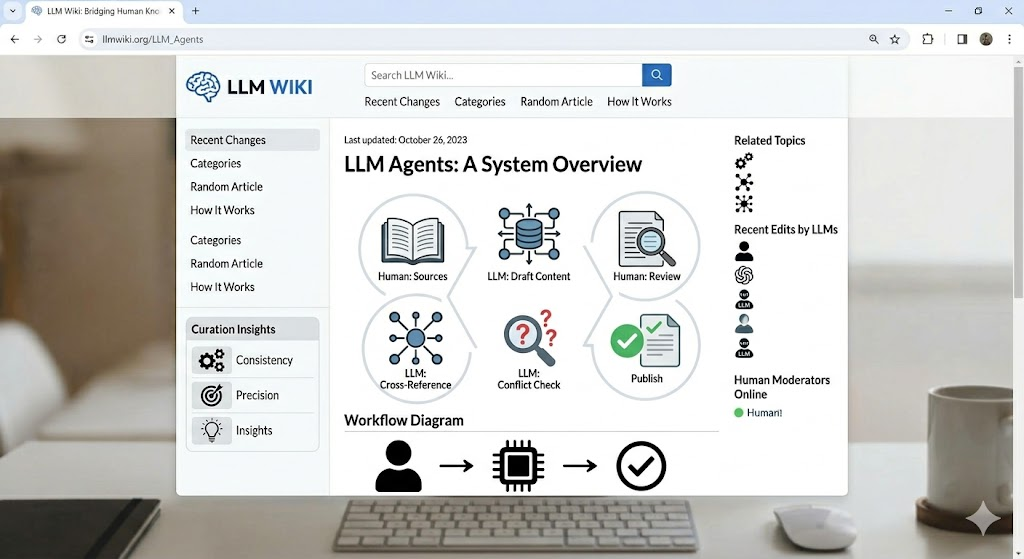
LLM Wiki
Context
The LLM wiki is a a pattern to building knowledge bases using LLMs, I heard about it from some reddit post or some youtube video (I don’t quite remember) that referenced Andrej Karpathy’s llm-wiki.md gist. I read it top to bottom in a moment and I was hooked, it was as if it was meant for me. Having participated recently in architecting and taking a RAG-based application to production much of what was said in the doc resonated completely and I knew it was a matter of time until I was going to do something with it.
In the days that came after I could not stop thinking about this idea. I obsessively communicated this to colleagues at work, friends and whomever lent an ear. I would link them the gist, show them the Obsidian graph (more on that later) and try to excite them into looking into it, even if I hadn’t put it into practice yet. I watched as some colleagues used it to built a product documentation repository and felt proud to spread the documentation bug.
I needed to get hands-on as soon as possible and build a prototype to validate the idea, to show something concrete rather than a whitepaper or some youtube video about a guy that did it for their personal notetaking. I wanted to build a real product that could solve a real need for my team and/or for the company.
So I decided to build a Platform Wiki.
Platform Wiki
The Platform Wiki, as Claude so eloquently puts it is: “A corporate knowledge base for the Platform Engineering team, maintained by Claude Code”. Based on Andrej Karpathy’s LLM Wiki pattern.
This wiki is a structured, interlinked knowledge base documenting the platform, its standards, processes, capabilities, and how to use it. Claude maintains the content; the human curates sources, asks questions, and guides the analysis.
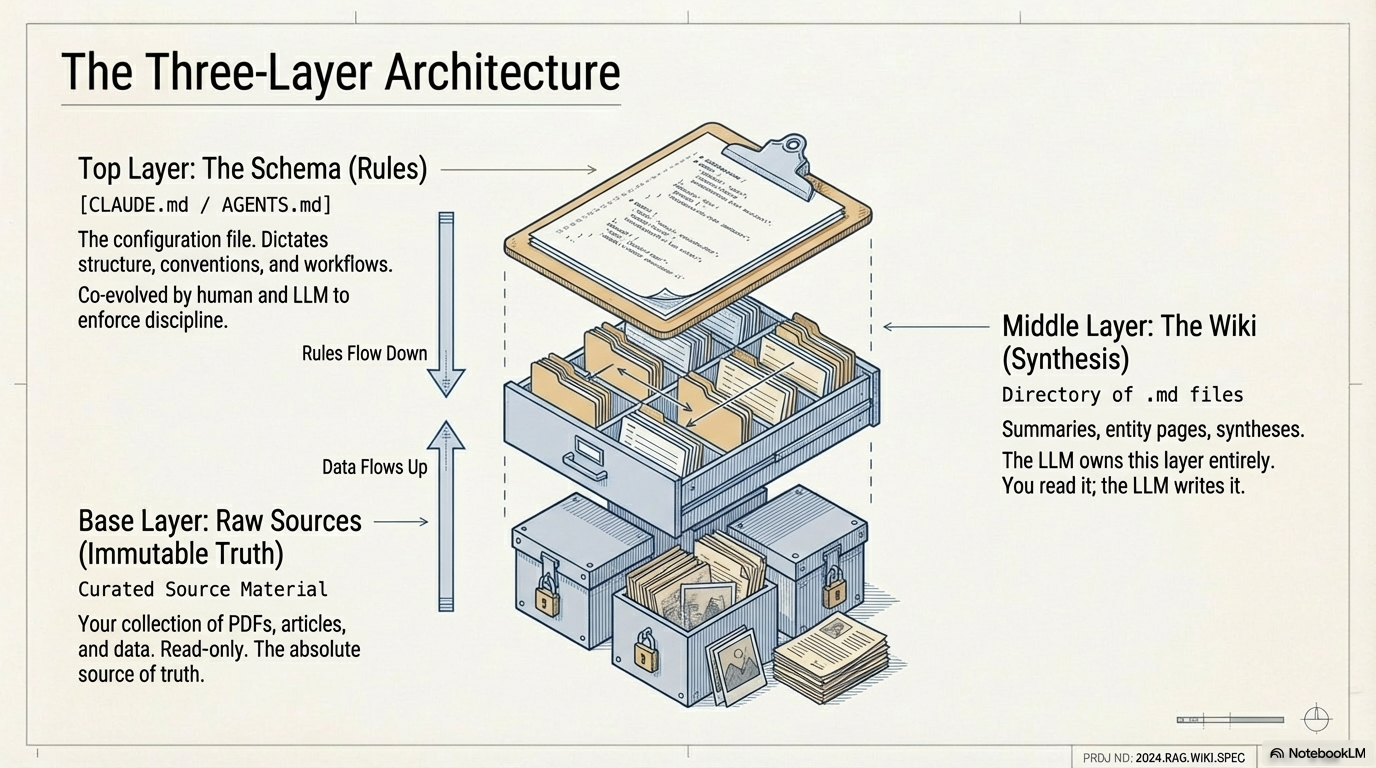
The pattern revolves around a thee-layer architecture.
- Top Layer: You are meant to provide the rules for how the model should behave in order to produce the outcome you expect (the schema)
- Middle Layer: You are meant to trust the LLM on this one, the LLM owns it and modifies it, you consume it. The world’s best information synthesis machine at your fingertips, and it will never get offended if you ask: “Hey, is this documented?”
- Base Layer: You are meant to provide raw sources as material for the model to process and organize in a meaningful and cohesive way. This is the source of truth and should never be modified by the LLM. (spoiler alert: it won’t be the source of truth for long)
Now, let’s dive a little bit deeper.
Top Layer: the Schema
If you are reading this and don’t know where the heck to start let me tell you: the initial schema does not need to be perfect. Mine wasn’t, and I will tell you some improvements I made so that hopefully you avoid them from the start if you agree on the approach.
I pulled an initial template from the Internet, from some YouTube video and modified it to my liking, you may just co-build it with your agent of choice by simply passing the Karpaty’s gist and crafting a plan together, you may pass the LLM this blog post as well (by all means!) and build the first iteration.
What we are talking about is a CLAUDE.md or AGENTS.md file in the project
that roughly covers the initial topics:
- Purpose: why you are building this (I just gave you mine for free in the section above 😉)
- Folder structure: depends on the content and preferences but at the very
least will include a folder for the base layer (eg.
raw/) and one for the actual wiki (eg.docs/) - Page format: structure for each article and mandatory information (important not only to organize the content but to instruct the model to connect related pages and how)
- Ingest workflow: steps to follow when processing each raw resource
- Question answering: what to do when a user asks a question
- Lint: how the model reports, maintains and prunes the pages when it encounters issues (and it will - trust me!)
- Rules: any other behavioral commandments you may enforce globally (styling, forbidden actions, ask user when in doubt, etc.)
A special comment about pager format: in this project the output will be .md
files, and this will have several implications / benefits. Firstly, it is
a light weight format with a hierarchical structure that is easy to navigate
by LLMs. Secondly, it is standardized and integrated into many tools that we
can leverage for rendering and exposing the content (more on that when
building the wiki). Finally, it is the format supported by my favorite note
taking tool, Obsidian, which will allow us to
explore and visualize the content locally, including the relationships between
the articles (this will be more clear in the end - I promise!).
I started with this and you can too, but if you want to do better (and I hope you do) I suggest you also consider some minor improvements I found out the hard way.
Learnings: a better and improved Schema
When processing the information I noticed that given that the raw material had a loose framework for documentation (you may find that yours has none at all) some of the articles did not fit one category in particular. For example, there may be articles that from the point of view of the information were well documented, but stretch over different typologies of documentation(how-to guides that include rationale about architecture decisions, or reference material that mix describing usage of an api with reflecting on the role of the api in the system, etc.).
This is not a big problem in itself, but as the documentation knowledge base grows the boundaries between information will be more and more significant, to prevent duplicated articles, to ensure that your users (or the model) finds what they are looking for efficiently. And.. given that you are building a library from the start what best as to tell the librarian where they should store each book, don’t you think ?
To address this issue I used the Diataxis framework. Diátaxis is “a systematic approach to technical documentation authoring”. I am no expert on it, but you don’t need to be in order to apply it. In fact, that is the recommended way of using it. Learn by using it on something, even if it is small. Diátaxis solves problems related to documentation content (what to write), style (how to write it) and architecture (how to organise it).
Diátaxis identifies four distinct needs, and four corresponding forms of documentation - tutorials, how-to guides, technical reference and explanation. It places them in a systematic relationship, and proposes that documentation should itself be organised around the structures of those needs. Put like that, it is exactly what we want as an outcome for our LLM maintainer, to aid them in their quest for outstanding and cohesive documentation.
I encourage you to read the primer on how to start with the framework, and maybe skim a bit on each of the four forms, and if it resonates with you there is no harm in that extra set of rules. After all, machines love well defined rules, and engineers love setting rules for their machines. ❤️
Just a small comment: I found that certain content may be too “transversal”
for the Diátaxis approach, like documentation for team standards or RFCs.
These typically include normative guidelines like “Use golang as backend
language, not python”, or may mix architecture proposal with code examples,
reference tables and explanations on background technical decisions. In this
specific case you may want to maintain the articles in a separate
standards/ folder where it can be used as source material, to be
referenced in other articles, as splitting the content may be
counterproductive to preserving the nature of the document.
Finally, I suggest you invest a few minutes to think about taxonomy. Remember
when I ranted about writers not being empathetic with their readers? Here’s
how you fix it: tag the freaking document to indicate who it is meant for!
If I write a document for the users of my internal developer platform I
shall tag it something like audience/developer , if I write a terraform
standard docs I might tag it domain/iac. I might include Diátaxis
capabilities as tags to make it searchable by need. Heck, you can even
combine them for a single article. If I write a how-to guide on how to
instrument the observability of an application I might tag it as
audience/developer, domain/observability, type/how-to. The
possibilities are endless!
Base Layer: the Raw sources
I bet you were expecting me to continue with the Middle layer (it is what I wanted to build by following this pattern after all), but before that I must say a word or two about the data we will ingest for that goal and what I learned through the process.
We’ve all read and heard about GIGO (Garbage in, garbage out). It’s almost a meme at this point with the popularization of RAG applications. Unfortunately it’s very true for this case. You may have the will to build the best wiki the world has ever seen, but if the initial documentation sources are garbage then what you will get as output is very well organized, interlinked garbage. Regardless, do not despair, even if your starting point is mediocre documentation, you can fix it slowly and one article at a time simply by using it as context and spending some quality time with Claude (or the agent of your choice) to match it with reality.
Let me give me real examples: I pulled my sources from an internal Confluence space of tens (or hundreds of articles), many of them written by people no longer in the company. Many of them are outdated. Now, you may think they are not worth to be ingested into the wiki unless they are perfectly in sync with the current state of things, and that’s were you would be wrong. The documents even if partially outdated include context and historical information about things that we used to do, about how the platform evolved, some may still be relevant now. If I discard the whole article and I make the wiki the new source of truth that content will be lost for ever. If the content is somewhat relevant my opinion is that it shall be included, I (and hopefully my colleagues) will take some minimal time to audit it and match it against our desired state. The LLM’s will be invaluable in this process, as they can help with analysis of the current infrastructure deployed, the current coding standards, the latest features available in the application or iac modules, and the humans will assist with the context and business decisions that are impossible to discover from an API endpoints. Together, AI and humans will co-create that initial state, as a one-time operation, and after that the LLM will take over as the owner and maintainer of the wiki. We will then be users of the documentation and shall steer the AI to keep evolving it as we simply go about with our day to day work.
Additionally, consider that raw sources are not static, and that they do not necessarily need to be fed manually. At the beginning, for the first iteration of the wiki, it may make sense to do so, but as the project grows you will want to detach the human intervention from the loop as much as possible, acting only as approver when it corresponds.
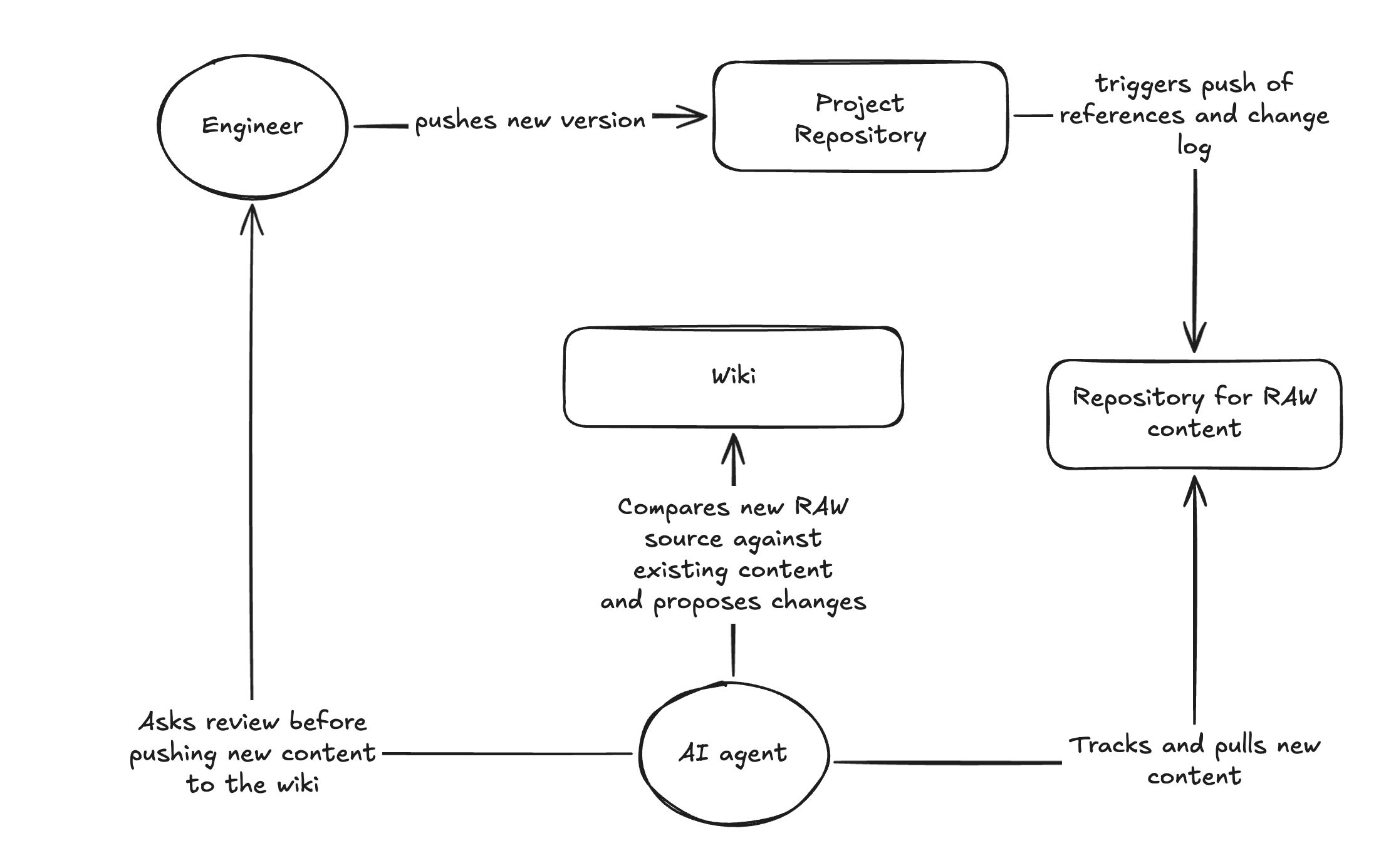
Now imagine you are using the Ship/Show/Ask workflow and that certain changes do not require direct approval before merging to the wiki. Next imagine that Ship and Show changes go through another AI agent (maybe a more potent model) instead of a human engineer. You’ve effectively achieved an agentic loop for 2/3 of the reference changes in your wiki.
Now, I know what you’ll say: “Pablo, wait what? Agentic loop? I thought we were building a wiki.”
Fair enough, I might have gotten a bit carried away. Let’s put a pin on it (for now) and get into the meat and potatoes: building the wiki.
Middle Layer: the Wiki
Processing the raw sources
Now this is the core of the project. We sat down with the harness agent of our choice and set the rules and strategy for processing input data, and we curated (more or less) a list of our desired content for ingestion. Now all that remains is to instruct our model to start “wiki-ing” the content.
The best (more efficient method) I’ve found is to export all the articles in bulk from wherever they may be and locate them to the local raw folder for the project. Once the articles are there you may instruct in steps that the model looks at certain documentation to find its place in the new wiki.
The agent shall ask questions, make proposals and raise conflicts that may exist in the documentation, all the while working on generating the relationships between the articles as they see fit.
For the process of analyzing the raw articles, processing and planning where to locate them I’ve found it’s best to use models such as Sonnet (or even Opus). Haiku in my experience starts hallucinating with a task this big and starts doing unacceptable actions, such as creating placeholder docs or articles with meaningless relations (that will later need to be cleaned up by a follow up revision). If you are going to spend tokens, you might as well spend them once and get the wiki in a decent acceptable state, that can later be leveraged by less potent models for follow up edits. For example: in my experience it is acceptable to let the main Sonnet session run subagents for bulk edits delegating the task to Haiku model, and later review the output. You may also (depending on your preference) limit the amount of parallel agents that can be run in the project, as by default your harness agent may attempt to run 9-10 sub agents in parallel if a transversal change happens in all the wiki. In my experience limiting the parallel agents to 2-3 at a time is good enough.
At last, the wiki has been populated with content for the first time. But, what next ? This deserves to be shared with the rest of the world, I’m sure you agree.
Making the content available
Sharing the content of the wiki can be achieved in several ways. But, much like I did for this very blog you are reading, I decided to go with a simple framework that allows us to concentrate in the content more that the form, having the page look good enough nonetheless.
Having chosen to create the articles in Markdown allows the use of something like Zensical, an open source toolchain to build static sites, made by the creators of Material for Mkdocs. In my opinion it has all the benefits of the previous Material (a project which I enjoyed to use very much), but with a better and more modern design. The scope of this project does not require many complex features, so even if the project is in alpha (at the time of writing this), it would not impact the use case. So for me, it was a no brainer.
The project itself can be hosted in a platform such as Gitlab / Github for versioning, and the CI can handle the build process as well as act as interface for revisions of the content. This would allow both for manual intervention (human in the loop for transcendental changes) and automatic edits (small and/or incremental changes). Having the project in git provides an extra layer of versioning that can be used for auditing the project in case the model goes wrong and content needs to be recovered, so the Top layer rules can be adapted to prevent bad edits from happening again, it also allows for key collaborators to pull the project directly and use it locally for their day to day, helping expand and improve the documentation by using it as context in their real world tasks (eg. Platform Engineers interact with Claude Code, ask it questions, which get turned into wiki content, while simultaneously using the wiki as context for planning implementations that adhere with the Platform’s team best practices and conventions).
Deploying the site can be done in multiple ways to make it available for other users. For a production-ready deployment a couple alternatives could be S3 + Cloudfront, or Cloudflare Pages. Although this is a bit out of scope of this article. If the service is to be consumed internally only, it could be containerized and deployed in Kubernetes also. For this last option you may want to check my blog project for inspiration:
- Self-hosted blog [part I] - (Hugo + Docker + Gitlab CI + K8s + Cloudflared)
- Self-hosted blog [part II] - (ArgoCD + Gitlab CI + K8s)
Regardless of the option you choose, the important part is that the outcome would be a browsable site with all the content for our platform users

Moreover, the content is searchable:
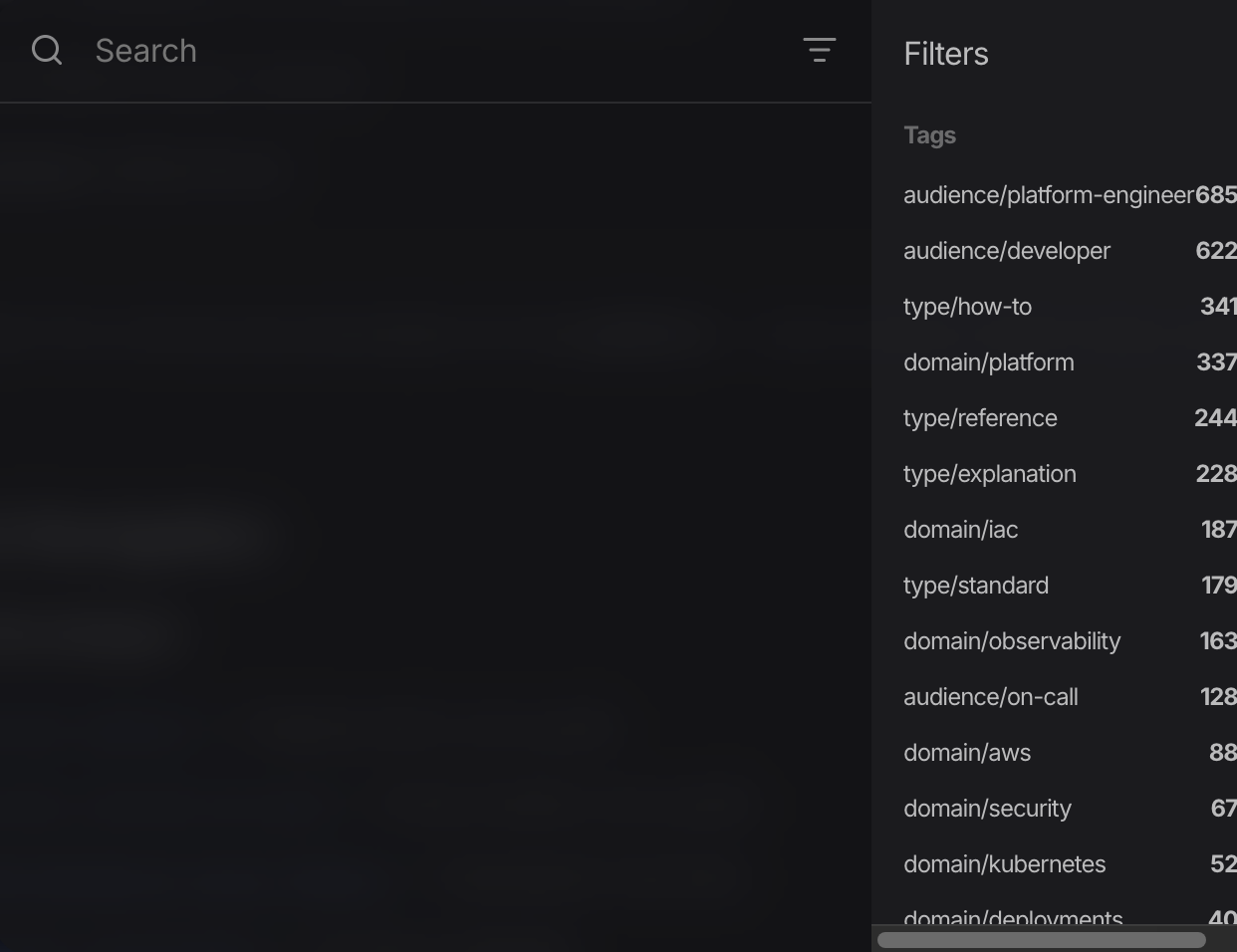
We may leverage our tagging taxonomy to filter the articles we are interested in, by audience, platform domain, Diátaxis content type, etc. This is where the time spent in the tags during the Base Layer phase pays off. By including tags in the front matter of the articles, we leverage Zensical’s support for tags in search, and instantly give us meaningful filters for the content of our wiki.
We may, of course, use key words to find the exact articles we are looking for using Zensical’s built-in search. Handy, right ?
Understanding the content
For those lucky fellows that can and would download the content to work on it locally, they could use Obsidian.
Obsidian has a useful graph function that allows us to understand the content of our wiki and the relationships that have been established between the different articles.
- White content are the raw articles that have already been processed
- Red are the documents that have already been created and interlinked
- Green nodes are the tags we have applied to the content
- Dark gray are files that no longer exist (references that must be fixed)
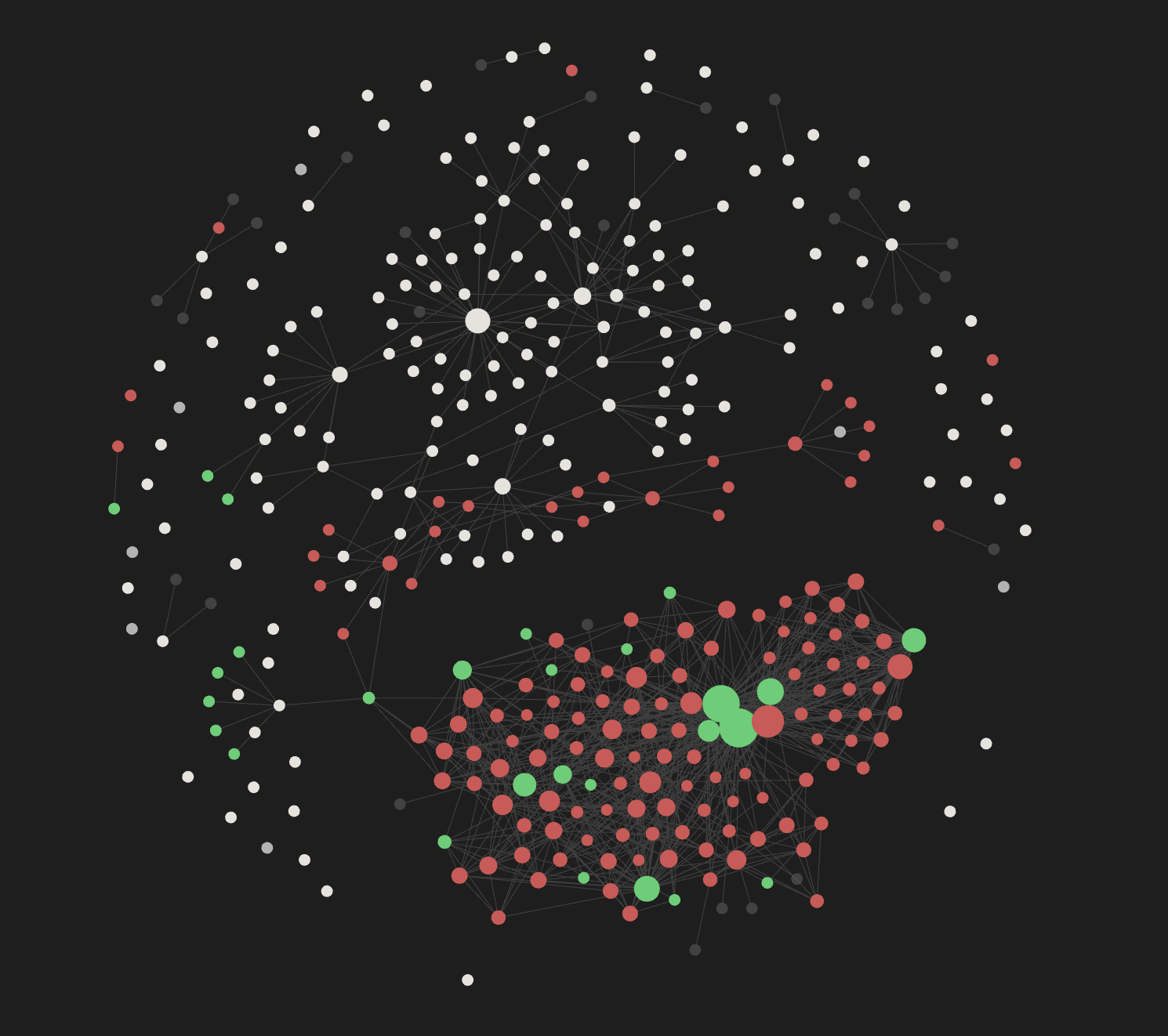
This is not only useful to understand how the LLM is able to navigate the content, but to identify visually things that may not be going well in our desired wiki. For example:
- you may identify that certain domain of the platform is notoriously behind in the documentation in regards to the rest by looking at the number of nodes related to a domain tag
- you may identify that filenames are not significant enough by looking at relationship between significant nodes in the graph, or by analyzing the weight of certain nodes in the graph
- you may identify orphaned nodes that should be linked to existing articles in the documentation
All of these and more will allow you to architect the wiki better, audit the work of the LLM, and think of new rules to enforce in order to generate better outcomes when processing the documentation.
The LLM wiki is supposed to be maintained by an LLM, but nowhere does it says that we cannot evaluate how the LLM maintains the LLM wiki. (Party game: try to read this phrase 3 times aloud without making any mistakes 🥳)
Final thoughts and next steps
Life 2.0 - Now with extra AI
I must admit that, like many people, I have approached AI in the past year with some scepticism. However, experiments like the LLM Wiki (yes - it is still an experiment / prototype at the time of writing this) challenge this interpretation and make me re-think the way we do things.
The transformational power of AI in our lives is undeniable, much like we cannot conceive going out of home without our cellphone, soon (if not already) we will be unable to provide value to our employers or even perform basic things efficiently if we do not master and incorporate AI in our day to day.
Either get on with it or you will be left behind before you know it.
AI & Platform Engineering
But, what does it mean for Platform Engineering ? Maybe a bit, maybe a lot.
At our core, Platform Engineering is a transversal enabler team, we provide the foundational components upon which our users build their solutions. That much hasn’t changed. However, as companies adopt AI as part of the development lifecycle they will require someone to establish the frameworks and guardrails for using it safely and efficiently. But that’s not all, I dare forecast that as we consider developers our “internal platform users”, soon we will be talking about AI agents as user personas of our platform ecosystem. As we humans provide the ideas, agents consume standards, tools, documentations and skills, the output gets then validated by other agents which escalate only when required before pushing to production. All of this requires us to architect an AI Platform that is “agentic friendly”.
So dear reader, if I have convinced you somewhat that AI in SDLC is not science fiction, maybe start thinking (if you haven’t already) what needs to be changed to support this new reality. At the very least, I hope you will help producing better documentation for those around you: now you have no excuse! 😈
Creating meaningful analytics dashboards without deeper data science knowledge, analyzing incidents with zero context of the underlying infrastructure, deploying prototypes with excellent documentation for architecture decisions in a day, etc. Seeing these implementations become reality have challenged my perception of AI tools and the incredible impact they can generate on technical and non-technical people. Now that AI goes beyond simple acceleration/automation into a state of semi-awareness, adapting to changes in systems, navigating roadblocks, planning and executing the future is part scary and exciting. It is certainly a privilege to experience it more closely than many, empowering those around to use their new found superpowers to let their creativity go beyond even our wildest dreams.
Not much left to say except: I, for one, welcome our new AI driven overlords.
Want to connect ?
🎉 Congratulations if you made it this far! 🎉
As mentioned before, this post was written with love by an actual human. AI was only used for linting, formatting and house keeping.
If you enjoy the content of this post (or any of my previous posts), please consider ☕ buying me a coffee ☕.
Do you have questions or comments about the solution ? Or perhaps you want to do something similar but you need a bit of help ?
Whatever the case may be feel free to write to me at [email protected] or via my LinkedIn page.
Thank you for reading, and for your support!